Cool project. I don't know loads about reverse engineering but was always super happy for the work done by the community over the years to reverse engineer Outpost 2 so that we can patch the game and create new content for it. For running on MacOS indeed Wine is the best way.
Cool to hear your working on a project zerodown524! BlackBox also started work on a map editor in python.
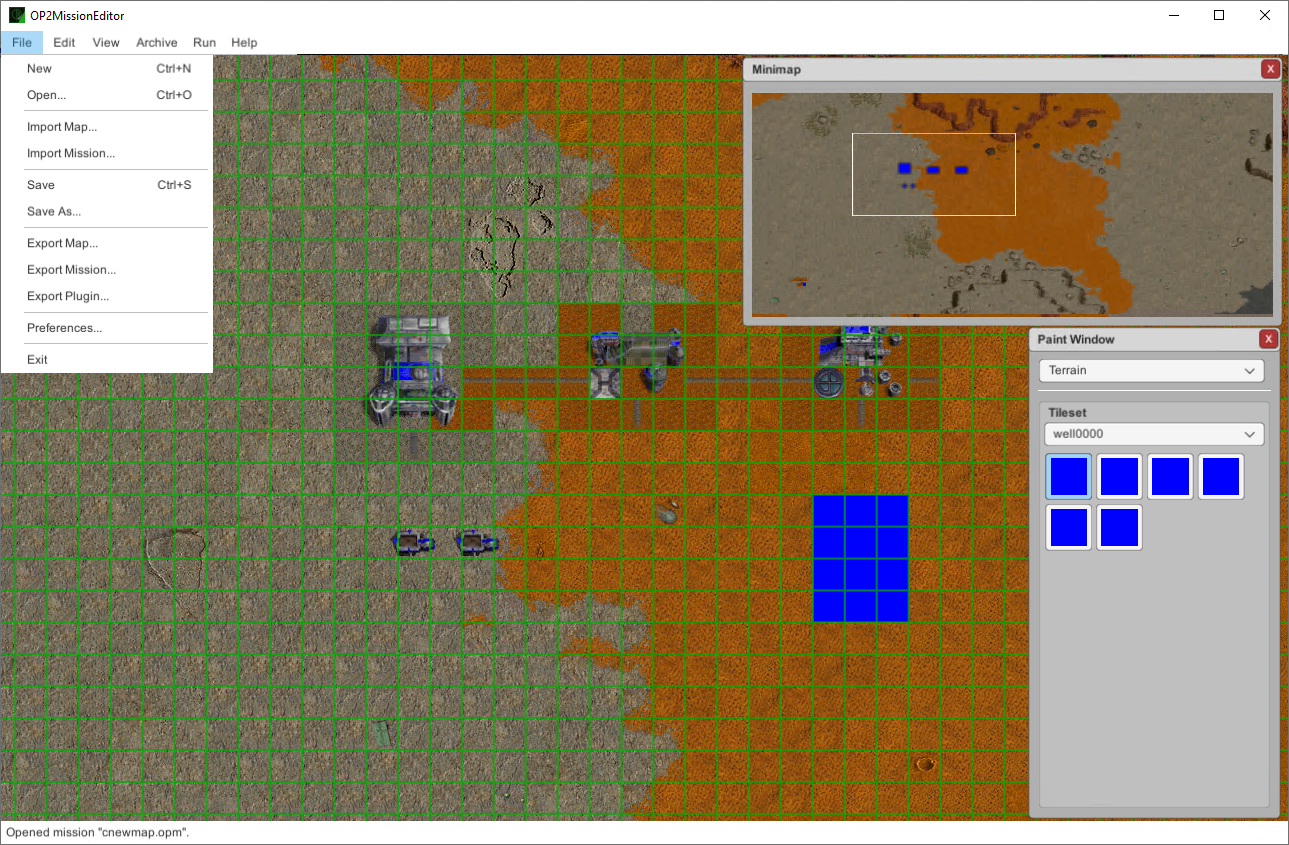
For map editors there are currently three working projects:
OP2Mapper2 - The VB6 editor from 2005
OP2Mapper3 - A new VB.NET editor from 2026
OP2MissionEditor- Unity / C# map editor from 2019

 Recent Posts
Recent Posts